


MongoDB alapok
Korábban kiveséztük szépen hogy mi fán is terem az a NoSQL, és összehasonlítottuk a hagyományos RDBMS rendszerekkel. Felmerült bennem azóta, hogy egy nagyon jó példa lehet a NoSQL használatára mondjuk a Web Scraping. Gondoljunk csak bele, hogy van egy weboldal, ahonnan adatokat gyűjtünk. Szépen fel is építjük a rendszerünket, megvan a back-end kód, meg egy előre megstrukturált adatbázis. Aztán hipp-hopp, hirtelen megváltozik a weboldal adattartama, egyes "mezők" eltűnnek, mások megjelennek. Elkerülendő azt, hogy az adatbázison minden ilyen alkalommal változtassunk, használhatunk akár NoSQL-t is. Hiszen: átvesszük az adatokat a weboldalról, mondjuk Spring Boot-tal beolvassuk, függetlenül attól, hogy milyen belső tartalma van, azt szépen átadjuk JSON-ként mondjuk a MongoDB felé, ahol az egyes entitásokat eltároljuk olyan mezőszerkezettel, amit éppen kaptunk. Aztán mehet rá mindenféle elemzés, amire épp szükségünk van.
No de, menjünk inkább bele a MongoDB használatába, szigorúan kezdőknek. Mit is kell tudnunk a MongoDB-ről?
- az egyik legelterjedtebb NoSQL adatbázis rendszer (ha megnéztek adatokkal foglalkozó álláshirdetéseket, szinte mindenhol előjön)
- NoSQL adatmodellre épült
- JSON vagy BSON formában tároja az adatokat
- nagy performancia jellemzi
- nagy skálázhatóság
- nincs SQL injection
A MongoDB dokument orientált adatbázis, ami azt jelenti, hogy minden adatunkat, entitásunkat dokumentumokban tároljuk, ami kb. így néz ki:
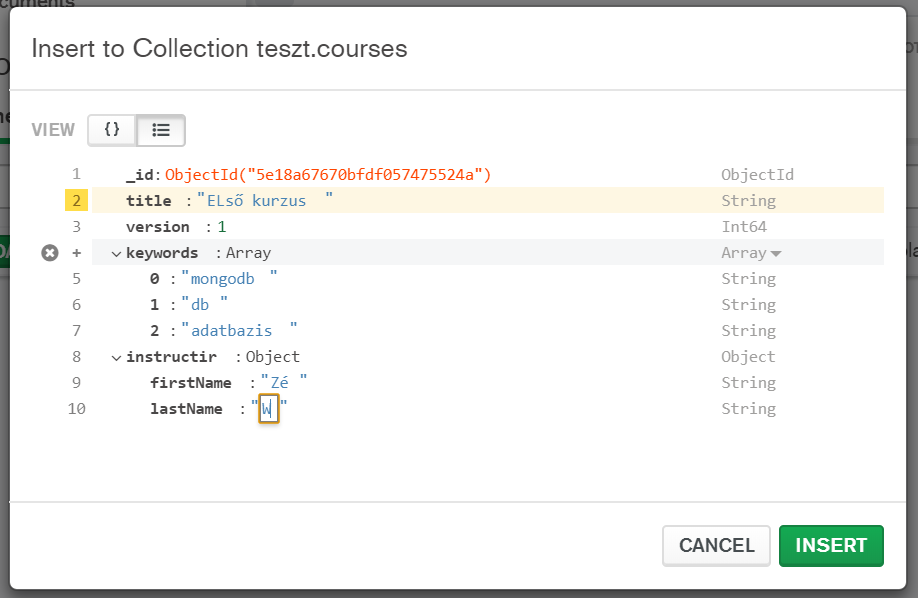
{ title: "Főcím",Láthatjuk, hogy ez igazából egy JSON. Minden egyes entitás külön dokumentumban tárolódik. Persze több dokumentum összekapcsolható, ami hasonló eredményt ad, mint a table a tradícionális SQL-ben (ennek a megnevezése Collection of Documents).
version: 1,
keywords: ["MongoDB", "DB"],
Instructor: {name: "Zoltán", lastName: "Werner"}}
Ahhoz, hogy nekiálljunk a MongoDB-vel való ismerkedésnek, első körben regisztráljunk a MongoDB oldalán, ahol egyúttal hozzunk is létre egy ingyenes adatbázist. Nem kell tehát a szervert magunknál telepíteni, elegendő a felhőben létrehozott adatbázis az ismerkedés idejére. Amire még szükségünk lesz, az a MongoDB Compass, amelyet kicsit később automatikusan le tudunk tölteni, amikor csatlakozunk az adatbázisunhoz.
Amit viszont érdemes letölreni, az az ATOM, amelyet érdemes használni akkor, amikor scripteket írunk a MongoDB-hez. Ha a MongoDB oldalon csatlakozni akarunk az adatbázisunkhoz, egyből meg is kérdezi, miképpen akarjuk ezt megtenni. Itt le is tudjuk szedni a Compass-t, ami grafikus megjelenítést ad számunkra az adatbázisról.
A clusterben a clusters/collection fülön hozzunk létre egy új adatbázist mondjuk teszt néven és egy új cluster-t hozzá pl. courses névvel.
Most, hogy létrehoztuk az adatbázisunkat, lépjünk is be a Compass-al, ahol az adatbázisban létre tudunk már hozni objektumokat, kezdjük is a sokat emlegetett dokumentummal, ami egy entitást és annak adatait tartalmazza. A tartalma lehet az alábbi:
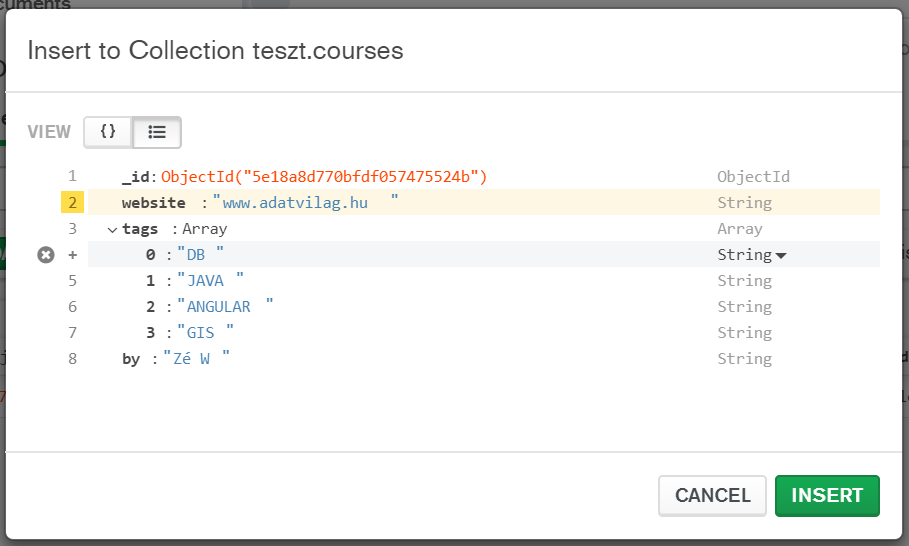
$match: meghívásával tudunk egy adott értékre rákeresni - elég az SQL-nek megfelelő SELECT-re gondolni. Ha beírjuk a következőt, akkor visszakapjuk azt a dokumentumot, amely ezt a mező/érték párost tartalmazza: {website: "www.adatvilag.hu" }. Láthatjuk, hogy a lekérdező nyelv a jól ismert JSON, nem szükséges külön SQL nyelvezetet bevetnünk.
$sort: sorba rendezés, a következő parancsra növekvő sorrendbe állítja a dokumentumokat (ahol nincs version, az 0-s értéket kap): { version: 1, title: 1 } Ebben az esetben növekvő a sorrend: első körben a version, második körben pedig a title alapján, -1 esetén pedig csökkenő sorrendben kérhetjük le az adatokat.
A következő példához hozzunk létre 4 új dokumentumot name és amount mezőkkel. Az amount mező tartalmazzon integer értékeket, a további példákban pedig az értékek szerint keresünk a dokumentumok között:
$gt: greater than, azaz egy megadott érték feletti értékeket tartalmazó dokumentumokat kapunk vissza: { amount: {$gt: 190}}
$lt: less than, itt pedig értelemszerűen a megadott értéknél alacsonyabbak lesznek az eredményhalmazban: {amount: {$lt: 190}}
$project: meglévő értékből tudunk kivonni értéket, pl. létrehozunk egy "left" nevű outputot, majd az amount mező SUM értékéből kivonunk 20-at: { left:{$sum:["$amount", -20]}}
$group: sokszor lehet szükség arra, hogy több dokumentum értékeit összegezzük, és egy outputot adjunk vissza egy adott id-hoz kapcsolódóan. Pl. vannak külön dokumentumaink az egyes felhasználókhoz, és minden egyes kiadásukat kapcsolódóan külön dokumentumban tároljuk le. Azaz a felhasználók nevét a name mezőben tároljuk, a kiadást pedig az amount mezőben. Mivel egy adott felhasználó neve azonos, ezért azt tudjuk id-nak használni, az amount-ot pedig össze tudjuk adni felhasználónként. Azaz van mondjuk egy Ildi nevű felhasználó, akinek van 2 dokumentuma 150 és 50 értékű amount-tal, illetve van egy Peti nevű felhasználó 2 külön dokumentumban 250 és 100 amount értékekkel. A 4 külön dokumentum outputa 2 dokumentum lesz, 200 Ildi esetében és 350 értékkel Peti esetében. Az ehhez szükséges aggregátor funkció a $group: { _id: "$name", totalAmount: { $sum: "$amount" }}. Itt az id lesz a name mező, hiszen az nem változik azonos felhasználónál, az új mező, amibe összegezni akarunk, a totalAmount nevet kapja, illetve összegezni akarunk ($sum), méghozzá az $amount mező értékét.
A fentiekben grafikus felületen használtuk a MongoDB-t, a továbbiakban pedig szkripteket fogunk létrehozni. Ehhez használhatjuk a már említett Atom nevű alkalmazást. Az Atom-ban létrehozott scripteket aztán a MongoDB Shell futtatásával elindtott felületeten lehet futtatni. A Shell futtatása cmd-ben: mongo --host "mongodb+srv://url" --username admin
Az alábbi paranccsal tudnk létrehozni egy új collection-t, majd azon belül több dokumentumot is:
db.students.insertMany( //a students collection-t hozzuk létreNézzünk egy lekérdezést innen Shell-en keresztül: db.students.find({enrolledClass: "Computer"}) - azokat kapjuk vissza, akik a Computer enrolledClass értékkel rendelkeznek
[
{name: "Zoli", age: 40, enrolledClass: "Math"}, //itt hozzk létre az első document-et
{name: "Dóri", age: 39, enrolledClass: "Computer"},//2. document
{name: "Feri", age: 38, enrolledClass: "Math"},//stb..
{name: "Évi", age: 37, enrolledClass: "Computer"},
{name: "Merci", age: 36, enrolledClass: "Math"} ]}
Ha mondjuk a 37 év fölötti felhasználókat akarjuk lekérdezni: db.students.find({age: {$gt: 37}})
Amennyiben módosítani szeretnénk az adatokon, akkor azt a következő módon tehetjük meg: db.students.update({"enrolledClass": "Math"}, {$set: {"enrolledClass": "Computer"}}, {multi: true}) Itt első lépésben megadjuk, hogy mit szeretnénk módosítani: {"enrolledClass": "Math"}, majd megadjuk, hogy mire szeretnénk módosítani: {$set: {"enrolledClass": "Computer"}}. Végül pedig, ha a teljes adatbázisban el akarjuk követni a módosítást, akkor: {multi: true} - ellenkező esetben csak az első dokumentumot módosítja
Dokumentum törlése pedig a következő módon történik: db.students.remove({"name": "Feri"})
Korábban a Compass-ban már futtattunk aggregálási funkciókat. Természetesen shell-ben is tudunk ilyet futtatni, pl. ha kíváncsiak vagyunk arra, hogy mekkora az átlagéletkora a felhasználóknak: db.students.aggregate({"$group": {"_id": null, averageAge: {$avg: "$age"}}}) Itt megadjuk, hogy nem szűrünk egy dokumentumra sem (azaz az összes dokumentumra számoljon): "_id": null, valamint létrehozzuk a kimeneti mezőnevet, benne lefuttatva az avg függvényt az age mezőre.
A következőkben létrehozunk egy array-t, amelybe elmentjük az összes felhasználó nevét: db.students.aggregate({"$group": {"_id": null, students: {$push: "$name"}}}), ezzel létrehoztunk egy olyan array-t, amelyet aztán egy applikációban fel tudunk aztán használni.
A már meglévő dokumentumok mezőstruktúrája is módosítható. Az alábbi script hozzátesz egy új, city nevű mezőt a dokumentumhoz:
db.students.insertMany( //a students collection-t hozzuk létreFentebb már létrehozunk egy array-t, viszont amennyiben az ismétlődő értékeket csak egyszer szeretnénk megjeleníteni az array-ben, abban az esetben a parancs a következő: db.students.aggregate({"$group": {"_id": null, "allCities": {"$addToSet": "$city"}}})
db.students.update({"name": "Zoli"}, {$set: {"city": "Budapest"}})
db.students.update({"name": "Dóri"}, {$set: {"city": "Praha"}})
db.students.update({"name": "Évi"}, {$set: {"city": "Lisboa"}})
db.students.update({"name": "Merci"}, {$set: {"city": "Praha"}})
A fenti szösszenet csak egy nagyon alap bemutatása a rendszernek, mindenkinek ajánlom hogy próbálja ki, találkozzon egy ilyen új dologgal is, ami remélhetőleg megmozgatja majd mindenki fantáziáját, és legközelebb nem csupán a hagyományos SQL-re fog majd gondolni, ha adattárolásról van szó.
A MongoDB kapcsán még egy rövid időre visszatérünk, a következő alkalommal ugyanis összedobunk egy MongoDB-JAVA Spring Boot alkalmazást, hogy megnézzük a kettő közötti kapcsolatot is.
